JavaScript�ɂ�����URL�G���R�[�h�̏���
|
���̃����́AJavaScript�ŃN�b�L�[����������ꍇ�̃|�C���g�����������AURL�G���R�[�h�Ɋւ��g���u����������Ă����������Ƃ�ړI�ɂ��Ă��܂��B���}���̕���3�͂�4�͂����ēǂ�Œ����č\���܂���B�Ȃ����̃����͂Ȃ�ׂ�IE�ł����������B �ڎ� 1. 1�@�N�b�L�[��URL�G���R�[�f�B���O 3. 3�@JavaScript�ɂ�����escape()��unescape()�� 4. 4�@JavaScript�ɂ�����encodeURI�AdecodeURI�AencodeURIComponent�AdecodeURIComponent |
HTML�e�L�X�g�ȊO�ɃE�F�u�E�T�[�o���u���E�U�ɏ���n����i�́AHTTP�������b�Z�[�W�̃w�b�_�����ɂ��̏����Z�b�g���邱�Ƃł��i�{�f�B�����ɂ͒ʏ�HTML�e�L�X�g������܂��j�B�T�[�o������̓N�b�L�[�ݒ�̃w�b�_�s�⎩���ō�������ʂȃw�b�_�s�ɏ����Z�b�g�ł��܂��B�����́i���O�A�l�j�̃y�A�̌`�����Ƃ�܂��B
HTML�e�L�X�g�O�œn�������́A�u���E�U��ʂɕ\������Ȃ��̂ŁA�\���̖ړI�ȊO�̃Z�b�V�����Ǘ��ȂǂɎg���܂��B�T�[�u���b�g�ɂ�����N�b�L�[�ɂ��Z�b�V�����ێ��̃��J�j�Y���́A�܂��������̓����𗘗p�������̂ł��B�Z�b�V�����ȊO�ɂ��N���C�A���g�Ƃ̊e��Ǘ����i�u���E�U�̃^�C�v��o�[�W�����A���[�U���Ȃǁj�A�Í����̂��߂̏��i��������Ȃǁj�̌�M�Ƃ��������p���l�����܂��B�܂��������N�b�L�[�̓N���C�A���g�ɒ~�ς����̂ŁA�J��Ԃ��\�����ʂɋ��ʂ̏����ŏ��ɃN�b�L�[�ő����Ă��܂����Ƃ��\�ł��B�܂��A�t�H�[���ɕ\�����Ȃ��ŕK�v�ȏ����T�[�o�ɕԂ����Ƃ��o���܂��B
���Ƃ���Tomcat�Ȃǂ̃T�[�u���b�g�E�G���W�����Z�b�V�����ێ��Ɏg���Ă���(�gjsessionid�h, ID)�̗ނ̃��J�j�Y���ȊO�ɁA�����Əڍׂɂ��̃Z�b�V�����̏��i���[�U�̖��O�Ȃǁj���N���C�A���g�ňێ����A�K�v�ɉ��������\������Ȃǂ��\�ɂȂ�܂��B
JavaScript�ɂ����ẮAHTTP�������b�Z�[�W�̃w�b�_�s�ڎ��o���@�\�͎c�O�Ȃ��炠��܂���B�������Ȃ���Window.document.cookie�I�u�W�F�N�g���g���āA�N�b�L�[��������̂���肪�\�ł��B�������Ȃ���A��q�̂悤��HTTP���b�Z�[�W�̃w�b�_�s��URL�G���R�[�h����˂Ȃ�܂���BASCII�����Z�b�g�����ōςމ��Ăƈ���ĉ�X�̂悤��2�o�C�g�̕����Z�b�g��W���I�Ɏg���ꍇ�́AURL�G���R�[�h�ɒ��ӂ��Ȃ���Ȃ�܂���B�F���Y�݂܂������N�����₷���̂͂��̓_�ł��傤�B
���̃����́AJavaScript�ŃN�b�L�[����������ꍇ�̃|�C���g�����������AURL�G���R�[�h�Ɋւ��g���u����������Ă����������Ƃ�ړI�ɂ��Ă��܂��B
1. �N�b�L�[��URL�G���R�[�f�B���O
|
�N�b�L�[��URL�G���R�[�f�B���O�̊�{�I�Ȓm�����K�v�ɂȂ�܂��̂ŁA�ŏ��ɂ��̃|�C���g������ł��������܂��B |
�ʏ�cookie�̓A�v���P�[�V�����E�T�[�o��HTTP�����̃p�P�b�g�̃w�b�_�����ɃZ�b�g���ău���E�U�ɓn���܂��B�Ⴆ��IBM�̃T�[�u���b�g�E�G���W���͎��̂悤��HTTP�̃w�b�_�s��HTTP�����ɂ��ăZ�b�V�����i�T�[�r�X�ƃN���C�A���g�Ƃ̑Ή��̎��ʁj�̈ێ����Ƃ낤�Ƃ��Ă��܂��B���̗�i�j�ł�sessionid�Ƃ����u���O�v�̕ϐ���LV�E�E�Ȃ�u�l�v�̑g��n���Ă��܂��B
|
Set-Cookie:
sessionid=LV140HYAAAABZQ....;Path=/ |
���̂悤��cookie��HTTP�p�P�b�g�̃w�b�_�s�ɂ���ē`�B�����̂ŁA2�o�C�g�������h;�h���h=�h�Ȃǂ̊댯�ȁi�v���g�R����Ӗ������j�������܂ށu���O�v��u�l�v������cookie���N���C�A���g�ɓn���Ƃ��́A�댯�ȃo�C�g�������܂܂Ȃ��悤URL�G���R�[�h���āA�o�C�g��Ƃ��ē`�B���˂Ȃ�܂���B
�}���`�o�C�g�������T�[�u���b�g�E�G���W���͉ʂ����Ă����F�����Ď����I��URL�G���R�[�h���Ă����̂��낤���������Ă݂܂��傤�B
���̃T�[�u���b�g�̓l�b�g��(http://ash.jp/java/hellocookie.htm)�Ō��J����Ă����v���O�����Ɉꕔ������������̂ł��B���̃v���O�����̓T�[�u���b�g�ɂ�����N�b�L�[�����Ɋւ���q���g�������Ă��܂��̂ŁA�ЂƂƂ��藝�����Ă��������B
|
import
java.io.*; import
java.net.*; import
javax.servlet.*; import
javax.servlet.http.*; /**
�N�b�L�[�ǂݏ����T�[�u���b�g **/ public
class HelloCookie0 extends HttpServlet { public void doGet (HttpServletRequest
req, HttpServletResponse res) throws ServletException, IOException { PrintWriter out; Cookie[] cookies; Cookie cookie; // Cookie�̎擾 cookies =
req.getCookies(); cookie = null; if (cookies != null){ for(int i=0;
i < cookies.length; i++) {
cookie = cookies[i];
if (cookie.getName().equals("HelloCookie")) { break; } } }
res.setContentType("text/html; charset=Shift_JIS"); out = res.getWriter(); HttpSession session =
req.getSession(); // Session�̎擾�Ə�������
session.setMaxInactiveInterval(600);
// 10���ԗL�� if (session.isNew())
{ // Cookie�̏����� cookie = new
Cookie("HelloCookie", "Hello World!");
cookie.setMaxAge(60);
// �L�����Ԃ�1���Ő�� res.addCookie(cookie);
out.println("<html><body>");
out.println("<h1>Write Cookie</h1>"); out.println("<p>�����[�h�����������B</p>");
out.println("</body></html>"); } else { // Cookie�̕\��
out.println("<html><body>"); out.println("<h1>"); for(int i=0;
i < cookies.length; i++) {
cookie = cookies[i];
out.println(cookie.getName()+" : "+ new
String(cookie.getValue().getBytes("8859_1"),
"Shift_JIS"));
out.println("<BR>"); } out.println("</h1>");
out.println("<p>Cookie�̃T���v���iHelloCookie0.java�j</p>");
out.println("</body></html>"); } } } |
���̃v���O������cookie = new Cookie("HelloCookie", "Hello World!");�Ƃ����s�́u�l�v�̕�����Ɋ�����댯�ȕ�����ݒ肷��ƃT�[�u���b�g�E�G���W���͂ǂ̂悤�ȉ����p�P�b�g�𑗐M���邩�����Ă݂܂��傤�B
a) �hHello ���{!�h�ƕς���telnet�̃\�t�g�E�G�A�ŃA�N�Z�X����Ǝ��̂悤�Ȍ��ʂ������܂��B�ŏ���2�s�i�s���܂ށj��telnet��������HTTP�v�����b�Z�[�W�ł��B����ȍ~���T�[�u���b�g�E�G���W���i�����ł�Tomcat�j���Ԃ���HTTP�������b�Z�[�W�ł��B�O�����w�b�_�����A�Ō��4�s���{�f�B�����ł��B����HTTP�����̃w�b�_����������ƁASet-Cookie�Ȃ�w�b�_�s��2�s���݂��邱�Ƃ���������ł��傤�B�ŏ��̓T�[�u���b�g���쐬�������̂ŁA��̂̓T�[�u���b�g�E�G���W�����Z�b�V�����ێ��ׂ̈ɍ쐬�������̂ł��B�]���āA�u���E�U�ɂ��Ă݂�ƁA2�̃N�b�L�[���n���ꂽ�Ƃ������ƂɂȂ�܂��B�u���E�U���ł����̃N�b�L�[�ɉ����ύX�������Ȃ���A�T�u�~�b�g�E�{�^���Ȃǂł���URL���ēx�A�N�Z�X�����Ƃ��ɂ́A�����̃N�b�L�[�͗L����������Ă��Ȃ�����̂܂܃T�[�o�ɕԂ���܂��B
|
GET
/examples/servlet/HelloCookie0 HTTP/1.0 HTTP/1.1
200 OK Content-Type:
text/html; charset=Shift_JIS Connection:
close Date:
Wed, 30 Oct 2002 03:45:24 GMT Server:
Apache Tomcat/4.0.4-b3 (HTTP/1.1 Connector) Set-Cookie:
HelloCookie=Hello ���{!;Expires=Wed, 30-Oct-2002 03:50:25 GMT Set-Cookie:
JSESSIONID=BAFB93DD6C7848751C369747B316DB6C;Path=/examples <html><body> <h1>Write
Cookie</h1> <p>�����[�h�����������B</p> </body></html> |
b) ���Ă���HTTP�������b�Z�[�W���݂�ƁAtelnet�̑Ή������Z�b�g��Shift_JIS�Ƃ����̂ŁA�gHello ���{!�h�̕����͕����������N�����Ȃ��Ő������ǂݏo����Ă��܂��B�܂��AIE(v6)��http://localhost:8080/examples/servlet/HelloCookie0�ƃA�N�Z�X���A�F�����PC��C:\WINDOWS\Cookies�ׂ�ƁA���̃N�b�L�[�������������Ȃ��Ŏ���Ă���̂��m�F�ł���ł��傤�B�ł��A���͂���́A���܂��܂��܂��������Ƃ��������Ȃ̂ł��B�h���{�h�Ƃ���������Shift_JIS�Ƃ��ăw�b�_�ɓ����Ă���̂ł����A���̃o�C�g��̂ǂ̃o�C�g��ASCII�́u�댯�ȕ����v�ɗ����Ă��Ȃ�����ł��B�X�ɁA���̎����ł̓��[�J���̃z�X�g���g���Ă���A�l�b�g���[�N����Ă͂��܂���B�l�b�g���[�N�̃m�[�h�ɂ���Ắi�Â��V�X�e���ł����j7�r�b�g�����`�����ꂸ�A�ŏ�ʂ�1�r�b�g(MSB)�͌�茟�o�⓯���Ȃǂ̖ړI�Ɏg���Ă�����̂�����܂��B���̂悤�ȃm�[�h������HTTP���b�Z�[�W���ʉ߂���ƁA���R�����������Ă��܂��܂��B
c) �댯�ȕ������܂ޕ����N�b�L�[�́u�l�v�̏ꏊ�ɃZ�b�g���ꂽ��ǂ��Ȃ�ł��傤���H�N�b�L�[�́u���O�v�Ɋ댯��1�o�C�g�������܂܂�Ă���ƃT�[�u���b�g�E�G���W���͗�O����悤�K�肳��Ă���̂ł����A�u�l�v�ɂ͂��̂悤�Ȑ��ǂ��������K�肳��Ă��܂���B�������h AAA ;B%BB�h�ƃX�y�[�X�ƃZ�~�R�������܂ޕ������o�͂��Ă݂悤�Btelnet�ł��̃T�[�u���b�g���Ăяo���Č���Ǝ��̂悤��HTTP�����p�P�b�g���ώ@���邱�Ƃ��ł��܂��B
|
HTTP/1.1
200 OK Content-Type:
text/html; charset=Shift_JIS Connection:
close Date:
Tue, 22 Oct 2002 04:39:25 GMT Server:
Apache Tomcat/4.0.4-b3 (HTTP/1.1 Connector) Set-Cookie:
HelloCookie=Hello AAA;B%BB;Expires=Tue, 22-Oct-2002 04:44:26 GMT �ȉ��ȗ� |
������u���E�U(IE6)�͂ǂ̂悤�Ɏ�荞����Explorer�Ō����C:\WINDOWS\Cookies�̃f�B���N�g���ɋL�^����Ă���t�@�C���͎��̂悤�ȃe�L�X�g�ɂȂ��Ă��܂��B�܂�X�y�[�X�͎t�������Z�~�R�����ȍ~�̓N�b�L�[�Ƃ��Ă͎t���Ă͂��Ȃ��̂ł��B�Z�~�R�����̓C���^�[�l�b�g�̐��E�ł́u��蕶���v�Ȃ̂ł��B
|
HelloCookie AAA localhost/examples/servlet/ 1024 1088345728 29522332 2383813024 29522331 * |
���̏͂ŏڂ����������܂����AURL�G���R�[�f�B���O��MSB��1�̃o�C�g��A�C���^�[�l�b�g��œ��ʂ̈Ӗ�������7�r�b�gASCII�������A7�r�b�gASCII�������g���č��������Ȃ��ő��邽�߂̎d�g�݂Ȃ̂ł��B
����܂ł̎������炨������̂悤�ɁA�N�b�L�[�̑��M�ɂ������Ă͖��O�A�l�Ƃ�URL�G���R�[�h���đ��邱�Ƃ���������܂��B�����NetScape�Ђ̉�����ł���������Ă��邱�Ƃł���܂��B�Ȃ��T�[�u���b�g�E�G���W�����Z�b�V�����ێ��ׂ̈�cookie���Z�b�g����Ƃ���URL�G���R�[�h���Ă͂��Ȃ��A�Ƃ�����URL�G���R�[�h�̕K�v�̂Ȃ����������g���Ă��܂���iURL�ϊ����Ă����̕ω��������܂���j�Btelnet�ȂǂŌ������₷���i�o�C�g�̂܂܂ł��u���O�v�����̂܂ܓǂ߂�j�悤�A�u���O�v��URL�G���R�[�h�Ɉ���������Ȃ��p���̕�����ɂ��邱�Ƃ��g���u���h�~�ɂȂ�ł��傤�B
���āA���̂悤�ɖ��O�ƒl�o����Java��URLEncoder�ŃG���R�[�h���č�����N�b�L�[�͂ǂ̂悤�Ƀu���E�U���������邩���ׂĂ݂܂��傤�B
|
String
namestring = "���t������b"; String
valuestring = "����Y"; namestring =
URLEncoder.encode(namestring, "Shift_JIS"); valuestring =
URLEncoder.encode(valuestring, "Shift_JIS"); cookie = new Cookie(namestring, valuestring); |
��������ƁAc:\windows\cookies�̃t�@�C���ׂĂ݂�Ǝ��̂悤�Ƀu���E�U��URL�G���R�[�h���ꂽ����������̂܂���Ă��邾�����ƌ������Ƃ��킩��܂��B��������ɖ߂��̂̓v���O���}�̐ӔC�Ƃ�����ł��B
|
%93%E0%8A%74%91%8D%97%9D%91%E5%90%62 %8F%AC%90%F2%8F%83%88%EA%98%59 localhost/examples/servlet/ 1024 3287822464 29522316 294622464 29522316 * |
�܂�Netscape�̍l�����́A�u�N�b�L�[��1�o�C�g�����ŁA�����S�ȕ����ō\�����ꂽ�������O�ƒl�̃y�A�Ƃ��đ��݂��Ă��邱�Ƃ�O��Ƃ��Ă���B�����łȂ�����������̂悤�Ȑ���ɂ��������ĕϊ����Ďg���̂̓v���O���}�̐ӔC�ł���v�Ƃ������̂ł��傤�B
2. URL�G���R�[�f�B���O�Ƃ�
|
�ǂ̂悤�ȃo�C�g��ł�7�r�b�g������ASCII�������g���ăC���^�[�l�b�g�̖Ԃ�ʉ߂����邽�߂̎d�g�݂Ƃ��Ă�URL�G���R�[�f�B���O�A���邢�͂��̋t��URL�f�R�[�f�B���O�ɂ��Ă��������ڍׂɗ������邱�Ƃɂ��܂��B |
���[��(SMTP)��HTTP�Ȃǂ̃p�P�b�g�́A�w�b�_���Ɉ���₻�̑����b�Z�[�W�̐���Ɋւ���ڂ����܂��B���̃w�b�_�͓r���́i�w�b�_�����߂����j�Q�[�g�E�G�[��������p����A�[����[�̃m�[�h�ɓ`�B�����̂ŁA�����̃m�[�h�ɗ����ł���R�[�h�ƕ����ŕ\������Ȃ���Ȃ�܂���B�w�b�_���ɓ��{��̂悤��2�o�C�g�̕���������ƁA�m�[�h�͂����1�o�C�g�����߂��悤�Ƃ��܂��B���̂Ƃ��ɂ��̃o�C�g�̂ǂꂩ���m�[�h�ɂƂ��ē��ʂ̈Ӗ������o�C�g�ł�������A���������ʂ������Ȃ��Ȃ��Ă��܂��܂��B�X�Ƀl�b�g���[�N�ɂ���Ă͊e�o�C�g�̈�ԏ�̃r�b�g(MSB)������������`���m�[�h�����݂��܂��B�]���Ăǂ̂悤�ȕ����ł����Ă����̂悤�Ȑ���̂Ȃ��ň��S�Ɋ����ߓI�ɓ`������邱�Ƃ��K�v�ɂȂ�܂��B��̓I�ɂ�7�r�b�g�Ŋ��u���S�ȁvASCII(American Standard Code for Information Interchange)�����Z�b�g����Ȃ镶����ɕϊ����ăC���^�[�l�b�g��ʂ��Ƃ������Ƃł��B���̂悤�Ȏd�g�݂Ƃ���URL�G���R�[�h���l�����܂����BURL�G���R�[�h�Ƃ����̂́A���Ƃ��ƃw�b�_����URL������2�o�C�g������䕶���ƕ���킵������������̂�h�~���邽�߂ɍl����ꂽ���炻���Ă�Ă��܂��B������������������ׂāu������v������ɕϊ�����͓̂s�����ǂ����Ƃ������A���b�Z�[�W�̃{�f�B�����̓`�B�ɂ��g���܂��B�{�f�B�����̕ϊ��ɂ͂����ЂƂ�MIME(Multi-Purpose Internet Mail Extensions)�̃G���R�[�f�B���O������܂��B�����2�o�C�g�̃o�C�i���E�f�[�^��3�o�C�g��7�r�b�gASCII�����ɕϊ�������̂ŁA�}���`���f�B�A���̓]���Ɏg���܂��B
URL�G���R�[�h�̎菇�͈ȉ��̂悤�ł��B
|
�@ ���{��̂悤��2�o�C�g�̕�����1�o�C�g���ɂƂ肾����ASCII�����Ƃ݂Ȃ��Ĉȉ��̕ϊ����s���B �A ���O�ƒl�ɂ���u���S�łȂ��v������"%xx"�Ƃ����G�X�P�[�v������ɕϊ�����B"xx"�͂��̕�����ASCII�l��16�i�\���������̂ł���B�u���S�łȂ��v�����ɂ�=, &, %, +��v�����g�ł��Ȃ�����,MSB�i�ŏ�ʃr�b�g�j��1�̕������܂ށB �B �S�Ă�ASCII�̃X�y�[�X������+�ɕϊ�����B �C ���O�ƒl��=��&�łȂ��łЂƂ̕�����ɂ���B�Ⴆ��name1=value1&name2=value2&name3=value3 |
���̕�����POST�v�����b�Z�[�W�̃{�f�B�����A���邢��GET�v���̃N�G��������A���邢�̓N�b�L�[�̃w�b�_�s�Ƃ��Ă͂ߍ��܂��̂ł��B
3. JavaScript�ɂ�����escape()��unescape()��
|
���悢��N���C�A���g�i�u���E�U�j�̂ق��ɘb���ڂ��܂��傤�BJavaScript�ł͓�����escape()��unescape()�̃O���[�o���������̂悤�ȖړI�Ŏg���邱�Ƃ�����܂����B�����������̊��͊��S��URL�G���R�[�h�Ή��łȂ���ɁA���̊��̒�`���r���ŕς���Ă��܂��A�����߂ł��܂���B |
���������JavaScript�ŃN�b�L�[��ǂݏo���Ƃ��AURL�G���R�[�h���ꂽ�N�b�L�[���ǂ̕����Z�b�g���Ɨ������ăf�R�[�h����̂ł��傤���HJava�ɂ����Ă�URLEncoder��URLDecoder�̓�̃N���X�ɂ����ĕ����Z�b�g�i������W3C���������Ă��邩��Ƃ�����UTF-8�𐄏�!�j���w�肷��悤�ɂȂ����̂��ŋ߂̂��Ɓij2sdk1.4����j�Ȃ̂ł��B
JavaScript�̌���d�l(escape/unescape)�ɂ͂��̂悤�ȋ@�\�����݂��Ȃ��̂������̂��ƂɂȂ��Ă���悤�ł��B�Ⴆ��escape()���\�b�h��NN(Netscape Navigator)��Shift_JIS�̃R�[�h��URL�G���R�[�h���ǂ��ŁAIE(Internet Explorer)�̓��j�R�[�h�\�L�i�G�X�P�[�v�E�V�[�P���X�ł�����UTF�ł͂Ȃ��I�j��Ԃ��Ă��܂��̂ł��B�t�����escape()���\�b�h������ɑΉ����܂��B�Ƃ��낪�����X�ɕ��G�ɂ��Ă���̂��AIE��escape()���͒ʏ��UTF-16��URL�G���R�[�h�i�Ⴆ��j2sdk1.4��URLEncoder.encode(str, �gUTF-16�h);�j�Ƃ͑S���قȂ�P�Ȃ郆�j�R�[�h�\�L�̕���������肾���A�Ƃ������ƂȂ̂ł��B�Ⴆ�Ύ��̂悤��htm�t�@�C����IE�ŊJ���ƁA
|
<HTML> <HEAD> <TITLE>JavaScript
escape()/unescape() functionarity test</TITLE> <META
HTTP-EQUIV="content-type" CONTENT="text/html;
charset=SHIFT_JIS"> </TITLE> <BODY> <PRE> JavaScript�ɂ�����escape���̃u���E�U�ɂ�鑊����`�F�b�N���� <SCRIPT
LANGUAGE="JavaScript"> s="���t������b=����Y"; document.writeln("original
string : "+s); s=escape(s); document.writeln("escaped
string : "+s); s=unescape(s); document.writeln("unescaped
string : "+s); </SCRIPT> </PRE> </BODY> </HTML> |
|
JavaScript�ɂ�����escape���̃u���E�U�ɂ�鑊����`�F�b�N���� original string : ���t������b=����Y escaped string : %u5185%u95A3%u7DCF%u7406%u5927%u81E3%3D%u5C0F%u6CC9%u7D14%u4E00%u90CE unescaped string : ���t������b=����Y |
�܂�%u�����Ȃ郆�j�R�[�h��16�i�\�L��Ԃ��Ă��邱�Ƃ���������ł��傤�B
���̂悤�ɁAIE��unescape()�����g���ēǂݏo���Ȃ�����URLEncoder.encode()���\�b�h���g���ăT�[�o���ŁAcookie���Z�b�g�����Ƃ��܂��傤�B
|
import
java.io.*; import
java.net.*; import
javax.servlet.*; import
javax.servlet.http.*; /**
�N�b�L�[�ǂݏ����T�[�u���b�g
**/ public
class HelloCookie extends HttpServlet { public void doGet (HttpServletRequest
req, HttpServletResponse res) throws ServletException, IOException { PrintWriter out; Cookie[] cookies; Cookie cookie; String urlencoding =
"UTF-16"; //�K�v�ɉ���"Shift_JIS"���hUTF-8�h�Ȃǂ����� // Cookie�̎擾 cookies =
req.getCookies(); cookie = null; if (cookies != null){ for(int i=0;
i < cookies.length; i++) {
cookie = cookies[i];
if (cookie.getName().equals("HelloCookie")) { break; } } }
res.setContentType("text/html; charset=Shift_JIS"); out = res.getWriter(); if (cookie == null)
{ //
Cookie�̏����� String namestring
= "���t������b"; String
valuestring = "����Y"; namestring =
URLEncoder.encode(namestring, urlencoding); valuestring =
URLEncoder.encode(valuestring, urlencoding); cookie = new
Cookie(namestring, valuestring); cookie.setMaxAge(300); // �L�����Ԃ�5���Ő��
res.addCookie(cookie);
out.println("<html><body>");
out.println("<h1>Write Cookie</h1>");
out.println("<P>");
out.println("<SCRIPT
LANGUAGE=\"JavaScript\">");
out.println("s=unescape(document.cookie);");
out.println("document.write(\"unescaped cookie :
\"+s);");
out.println("</SCRIPT>");
out.println("</P>"); out.println("<p>�����[�h�����������B</p>");
out.println("</body></html>"); } else { // Cookie�̕\��
out.println("<html><body>");
out.println("<h1>");
out.println(URLDecoder.decode(cookie.getValue(), urlencoding));
out.println("</h1>");
out.println("<p>Cookie�̃T���v���iHelloCookie.java�j</p>");
out.println("</body></html>"); } } } |
���̂Ƃ�telnet�ŃA�N�Z�X����Tomcat�����M����HTTP�����p�P�b�g��Set-Cookie�s�ׂ�Ǝ��̂悤�ɂȂ��Ă��܂��B
|
Set-Cookie:
%FE%FF%51%85%95%A3%7D%CF%74%06%59%27%81%E3=%FE%FF%5C%0F%6C%C9%7D %14%4E%00%90%CE;Expires=Wed,
23-Oct-2002 04:33:23 GMT |
�܂�u���t������b�v�̕������%FE%FF%51%85%95%A3%7D%CF%74%06%59%27%81%E3�ɁA�u����Y�v�̕������%FE%FF%5C%0F%6C%C9%7D%14%4E%00%90%CE�ɕϊ�����Ă��܂��BFEFF�Ȃ镶����͂��ꂪBOM�i�o�C�g���}�[�N�j�ŁA�r�b�O�G���f�B�A���ł��邱�Ƃ��Ӗ����܂��B���ꂪ������UTF-16�R�[�h�\���Ȃ̂ł��B�u���t������b=����Y�v�Ƃ���������̏ꍇ�͎��̂悤�ɕϊ�����܂��B
|
%FE%FF%51%85%95%A3%7D%CF%74%06%59%27%81%E3%00%3D%5C%0F%6C%C9%7D%14%4E%00%90%CE |
���R�̂��ƂȂ��炱�̃T�[�u���b�g�̏o�͂�IE�� unescape()���͐������t���Ă͂���܂���B
IE�����o���u���t������b=����Y�v�̃G���R�[�f�B���O�͂����قǎ������悤�ɒP�Ȃ郆�j�R�[�h�\�L��
|
%u5185%u95A3%u7DCF%u7406%u5927%u81E3%3D%u5C0F%u6CC9%u7D14%u4E00%u90CE |
�ł����āA����Ƃ͑S���قȂ��Ă��܂��B���܂����h=�h�Ƃ��������̓��j�R�[�h�\������Ȃ��ŒP�Ȃ�%3D�Ƃ���ASCII�����Ƃ��ď�������Ă��܂��Ă��܂��B�ǂ�����%u003D�Ƃ��Ȃ��̂ł��傤���BECMA-262�ɏ����������̂̂悤�ł����A���������̂ł��B���������āuIE�̏ꍇ�͉�������escape()��unescape()���͎g��Ȃ��ق����ǂ��v�Ƃ����̂����_�ł��B
���Ȃ݂ɐ�قǂ̃T�[�u���b�g�� String urlencoding = "Shift_JIS";�ƕύX���āA�����NN�ŌĂяo���Ǝ��̂悤�ɐ���ɕ\������܂��B
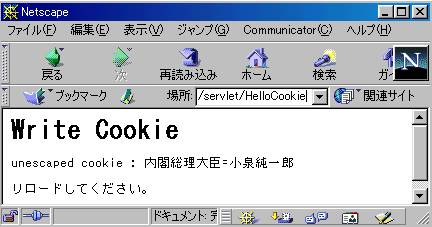
�A��NN�ł�Shift_JIS��URL�G���R�[�h���g���Ă���Ζ�肪�Ȃ����Ƃ����Ǝc�O�Ȃ��炻���ł͂���܂���B�Ⴆ�u���t������b ����Y�v�ƊԂɔ��p�X�y�[�X�����������Ă����NN�́u���t������b+����Y�v�ƃv���X�L���ɕς��Ă��܂܂��܂��B�����URL�G���R�[�h�̉��߂̑���ɂ����̂ŁAj2sdk1.4�ł̓X�y�[�X���h+�h�����ɕϊ�����̂ɁANN��escape()���̏ꍇ�̓X�y�[�X��%20�ɕϊ����܂��B�ׂ������Ƃł���j2sdk1.4�ł͑��ē��ꂵ�ā�nn�̌`���ŕϊ�����̂�NN��escape()���̏ꍇ�̓o�C�g�ɒ������Ƃ��Ɋ댯�ȕ����łȂ�����̂܂�1�o�C�g�����Ƃ��ĕϊ����܂��B��̓I��"���t������b ����Y"�Ȃ镶����̕ϊ��̑���������ƁF
|
J2sdk1.4��URLEncoder.encode() |
%93%E0%8A%74%91%8D%97%9D%91%E5%90%62 +%8F%AC%90%F2%8F%83%88%EA%98%59 |
|
NN��JavaScript��escape() |
%93%E0%8At%91%8D%97%9D%91%E5%90b %20%8F%AC%90%F2%8F%83%88%EA%98Y |
�ȏ�̂��Ƃ���JavaScript��escape()��unescape()��IE��NN�o���ɖ�肪����AWeb�A�v���̂悤�ɃT�[�o�^IE�^NN�Ƃ��ɖ��Ȃ������������悤�Ƃ���Ƃ����̊��͎g���ׂ��łȂ��A�ƌ��_����܂��B
4.
JavaScript�ɂ�����encodeURI�AdecodeURI�AencodeURIComponent�AdecodeURIComponent
|
�o�[�W���� |
��\�I�ȃu���E�U |
���l |
|
1.0 |
NN2.0 �̓r���` IE3.0 |
JavaScript �̃I���W�i���̎d�l |
|
1.1 |
NN3 IE3.02+JScript1.3�p�b�` |
Array object��C�x���g�Ȃǂ̒lj� |
|
1.2 |
NN4.0 �` 4.05 IE4 |
Layer/DIV �@�\, CSS�̒lj� |
|
1.3 |
NN4.06 �` IE5.0 �` |
unicode�Ȃǎ�� ECMA-262�Ή� |
|
1.4 |
NN5( �J�����~ ) |
catch/try ���̗�O�����Ȃ�( ECMA-262�Ή� ) |
|
1.5 |
Mozilla5( NN6 ) IE6�` |
ECMA-262 3rd Edition |
|
2.0 |
? |
ECMA-262 4th Edition |
|
encodeURI |
||
|
���̕����� |
IE6�̏o�� |
NN7�̏o�� |
|
���t������b ����Y |
%E5%86%85%E9%96%A3%E7%B7 %8F%E7%90%86%E5%A4%A7%E8%87%A3 %20%E5%B0%8F%E6%B3%89%E7 %B4%94%E4%B8%80%E9%83%8E |
%E5%86%85%E9%96%A3%E7%B7 %8F%E7%90%86%E5%A4%A7%E8%87%A3 %20%E5%B0%8F%E6%B3%89%E7 %B4%94%E4%B8%80%E9%83%8E |
|
���t������bX����Y |
%E5%86%85%E9%96%A3%E7%B7 %8F%E7%90%86%E5%A4%A7%E8%87%A3 X%E5%B0%8F%E6%B3%89%E7 %B4%94%E4%B8%80%E9%83%8E |
%E5%86%85%E9%96%A3%E7%B7 %8F%E7%90%86%E5%A4%A7%E8%87%A3 X%E5%B0%8F%E6%B3%89%E7 %B4%94%E4%B8%80%E9%83%8E |
|
encodeURIComponent |
||
|
���̕����� |
IE6�̏o�� |
NN7�̏o�� |
|
���t������b ����Y |
%E5%86%85%E9%96%A3%E7%B7 %8F%E7%90%86%E5%A4%A7%E8%87%A3 %20%E5%B0%8F%E6%B3%89%E7 %B4%94%E4%B8%80%E9%83%8E |
%E5%86%85%E9%96%A3%E7%B7 %8F%E7%90%86%E5%A4%A7%E8%87%A3 %20%E5%B0%8F%E6%B3%89%E7 %B4%94%E4%B8%80%E9%83%8E |
|
���t������bX����Y |
%E5%86%85%E9%96%A3%E7%B7 %8F%E7%90%86%E5%A4%A7%E8%87%A3 X%E5%B0%8F%E6%B3%89%E7 %B4%94%E4%B8%80%E9%83%8E |
%E5%86%85%E9%96%A3%E7%B7 %8F%E7%90%86%E5%A4%A7%E8%87%A3 X%E5%B0%8F%E6%B3%89%E7 %B4%94%E4%B8%80%E9%83%8E |
|
�J�e�S�� |
���� |
|
�\�� |
, / ? : @ & = + $ , |
|
�G�X�P�[�v���Ȃ����� |
�A���t�@�x�b�g, 10�i����, - _ . ! ~ * ' ( ) |
|
�X�R�A |
# |
����������document.cookie�łƂ肾��������������̂܂ܖ߂��Ƃ���decodeURI()���g�����ƂɂȂ�܂��B�N�b�L�[�́u�l�v��u���O�v����������Ƃ���decodeURIComponent()�Ȃǂ��g���Ƃ��Ă��܂��B�����JavaScript���N�b�L�[���i���O�A�l�j�̃I�u�W�F�N�g�̏W���ł͂Ȃ��A�P�Ȃ镶����Ƃ��Ď�舵���������ߐ��������ł��B������܂��v���O���}�ɍ�����^����v���ɂȂ�܂��B������͂��̂悤�ɉ��肳��邱�ƂɂȂ�ł��傤�B
���Ȃ݂ɁF
�@�h %E5%86%85%E9%96%A3%E7%B7%8F%E7%90%86%E5%A4%A7%E8%87%A3%20%E5%B0%8F%E6%B3%89%E7%B4%94%E4%B8%80%E9%83%8E�h
�Ȃ镶����́AdecodeURI()��decodeURIComponent()�������h ���t������b=����Y�h���������܂��B
�������Ȃ���A�݊����̖�肪����̂ł��B�܂�j2sdk1.4��URLencoder.encode(String,�hUTF-8�h)���G�X�P�[�v���镶���Z�b�g�ƁAencodeURI�̃G�X�P�[�v���镶���Z�b�g���قȂ�̂ł��B�X�ɁAj2sdk1.4��URL�G���R�[�h����������decodeURI���ł͐������ǂݎ��Ȃ����ƂɂȂ�̂ł��B
encodeURI�����G�X�P�[�v���Ȃ������͉��\�̂悤�ł����B
|
�J�e�S�� |
���� |
|
�\�� |
, / ? : @ & = + $ , |
|
�G�X�P�[�v���Ȃ����� |
�A���t�@�x�b�g, 10�i����, - _ . ! ~ * ' ( ) |
|
�X�R�A |
# |
EncodeURIComponent���̂ق��̓G�X�P�[�v���Ȃ�������ɂ͗\�����܂܂�Ȃ��̂��Ⴄ�Ƃ���ł��B
�������Ȃ���Aj2sdk1.4��URLencoder.encode(String,�hUTF-8�h)���G�X�P�[�v���Ȃ������͉��\�̂悤�ɂȂ��Ă��܂��B�Ԏ����ߕ����̕������G�X�P�[�v���Ȃ������A�A���X�y�[�X(SP)���h+�h�ɒu������������̓G�X�P�[�v���Ȃ������ł��B
|
Char Decimal Hex �@�@Char �@ Decimal �@ Hex
NUL 0 0
SOH 1 1 STX 2 2
ETX 3 3 EOT 4 4
ENQ 5 5 ACK 6 6
BEL 7 7 BS 8
8
HT 9 9 NL 10 a
VT
11 b NP 12 c
CR
13 d SO 14 e
SI
15 f DLE 16 10
DC1 17 11 DC2 18 12 DC3 19 13 DC4 20 14
NAK 21 15 SYN 22 16
ETB 23 17 CAN 24 18
EM
25
19 SUB 26 1a
ESC 27 1b FS 28 1c
GS
29
1d RS 30 1e
US
31
1f SP 32 20
!
33
21 " 34 22
#
35
23 $ 36 24
%
37
25 & 38 26
'
39
27 ( 40 28
)
41
29 * 42 2a
+
43
2b , 44 2c
- 45 2d . 46 2e
/
47
2f 0 48 30
1
49
31 2 50 32
3
51
33 4 52 34 5 53 35 6 54 36
7
55
37 8 56 38
9
57
39 : 58 3a
;
59
3b < 60 3c
=
61 3d > 62 3e
?
63
3f @ 64 40 A 65 41 B 66 42
C
67
43 D 68 44
E
69
45 F 70 46
G
71
47 H 72 48
I
73
49 J 74 4a
K
75
4b N 78 4e
O
79
4f P 80 50
Q
81
51 R 82 52
S
83
53 T 84 54
U
85
55 V 86 56
W 87 57 X 88 58
Y
89
59 Z 90 5a [ 91 5b \ 92 5c
]
93
5d ^ 94 5e
_ 95 5f ` 96 60
a 97 61 b 98 62
c
99
63 d 100 64
e
101
65 f 102 66
g
103
67 h 104 68
i
105
69 j 106 6a
k
107
6b l 108 6c
m
109
6d n 110 6e
o
111
6f p 112 70 q 113 71 r 114 72
s
115
73 t 116 74
u
117
75 v 118 76
w
119
77 x 120 78
y
121
79 z 122 7a { 123 7b | 124 7c
}
125
7d ~ 126 7e DEL 127 7f |
�]���Ď����T�[�u���b�g�̃v���O�����ŁA
|
String namestring = "URL�G���R�[�h�̎���"; String valuestring = "
!\"#$%&'()*+"+'\u002c'+"-./01289:;<=>?@ABCXYZ[\\]"+'\u005e'+'\u005f'+'\u0060'+"abcxyz{|}"+'\u007e'; namestring =
URLEncoder.encode(namestring, urlencoding); valuestring = URLEncoder.encode(valuestring, urlencoding); |
�Ƃ��āA�f\u0020�f�����f\u007e�f�܂ł̕������ǂ̂悤��URL�G���R�[�h����A����JavaScript��decodeURI�����ǂ̂悤�Ƀf�R�[�h���邩�������Ă݂�Ǝ��̂悤�Ȍ��ʂ������܂��B
|
undecoded
cookie :
URL%E3%82%A8%E3%83%B3%E3%82%B3%E3%83%BC%E3%83%89%E3%81%AE%E5%AE%9F%E9%A8%93 =+%21%22%23%24%25%26%27%28%29*%2B%2C-.%2F01289%3A%3B%3C%3D%3E%3F%40ABCXYZ%5B%5C%5D%5E_%60 abcxyz%7B%7C%7D%7E decoded
cookie : URL�G���R�[�h�̎���=+!"%23%24%%26'()*%2B%2C-.%2F01289%3A%3B<%3D>%3F%40ABCXYZ[\]^_`abcxyz{|}~ |
�܂�decodeURI���͗\���ƃX�R�A�����ւ̃f�R�[�h�͂����A���̂܂܃G�X�P�[�v�\����Ԃ��Ă��܂��Ă���̂ł��B���ۂ�encodeURI�ŃG�X�P�[�v���Ȃ������ւ̃f�R�[�h���Ă���f�R�[�h�̑ΏۂƂȂ�܂��B
�u�����̕������g��Ȃ��v�Ƃ����̂��ЂƂ̉����@�����m��Ȃ����A���܂�ǂ���i�Ƃ͂����܂���B
�܂��A�N�b�L�[���ꊇ�G���R�[�h����ꍇ��encodeURIComponent�����g���Ă͂����Ȃ����Ƃ��Y��Ȃ��ʼn������B
5. ����ł͈�̂ǂ�����悢���H
����ł͎c�O�Ȃ���encodeURI�AdecodeURI�AencodeURIComponent�AdecodeURIComponent�Ƃ����������g���Ȃ��u���E�U�������������p����Ă��錻��ł��邱�ƁA�����̊���Java 2�v���b�g�z�[����URL�G���R�[�h�Ƃ̌݊������Ȃ����Ƃ����Ă��āAcookie��JavaScript���g���ăN���C�A���g�^�T�[�o�Ԃŏ���������ꍇ�ɂ͂ǂ�������悢�̂ł��傤���H���ǂ��̂悤�Ȍ��_�ƂȂ�܂��B
���_
JavaScript���T�[�o���Z�b�g�����N�b�L�[����������悤�ȃA�v���P�[�V�����ɂ����ẮF
1) �N�b�L�[�̖��O�ƒl�Ƃ���URL�G���R�[�h���邱�Ƃ���������邪�A���O�́u�댯�v�łȂ��iURL�G���R�[�h�ɉe������Ȃ��j��������Ȃ�p��������Ɍ��肷�ׂ��ł��Btelnet�Ȃǂ̃c�[���ɂ�錟��f�o�b�O�̕ւ�z���������̂ł��B
2) NN�y��IE��escape()��unescape()���͖�肪����̂Ŏg���Ă͂Ȃ�܂���BEncodeURI()�AdecodeURI()�AencodeURIComponent()�AdecodeURIComponent()���A�Â��o�[�W�����̃u���E�U�ł͑Ή��ł��Ă��Ȃ����Aj2sdk1.4�Ƃ̌݊����̖�肪����܂��B����J2sdk1.4��java.net�̃p�b�P�[�W�ɂ���URLEncoder.encode()�y��URLDecoder.decode()�Ɠ����@�\��������JavaScript�̊���p�ӂ���̂��x�X�g�ł��B��������Ύ������ǂ̃u���E�U��̂ǂ̃o�[�W�����ő����Ă��邩��JavaScript�͎��ʂ���K�v���Ȃ��Ȃ�܂��B
URL�G���R�[�h��UTF-8�ɓ��ꂷ��B�����EncodeURI()�AdecodeURI()�AencodeURIComponent()�AdecodeURIComponent()��UTF-8���g���Ă��邩��Ƃ������R�ł��B�܂�Java�̎d�l�ɂ����Ă�UTF-8�𐄏����Ă��܂��B���{��ł͋ɂ߂Č����������̂ł����A���̐��E�ł�UTF-8��W���I�Ɏg�����ق�������ł��傤�B
6. UTF-8��URL�G���R�[�h�E�f�R�[�h���̗�F
|
���j�R�[�h�i1�o�C�g�A2�o�C�g���A4�o�C�g��������j���O���ƃo�C�g��Ƃ��Ă���肷��`���iUnicode Transfer Format: UTF�j�ɂ�UTF-8��UTF-16���ǂ��g���܂��B�����UTF-8�ɂ��URL�G���R�[�h����������̂ŁAUTF-8�ւ�URL�ϊ��@���Љ�܂��B���̂܂g���Ƃ͐\���܂���B���̃v���O�������Q�l�ɂ��Ă���������K���ł��B |
UCS����UTF-8�ւ̕ϊ��@�͎��̃e�[�u���Ɏ������悤�ɂȂ�܂��B
UCS����UTF-8�ւ̕ϊ��@
|
UCS-2 (UCS-4) |
�r�b�g�p�^�[�� |
��P�o�C�g |
��Q�o�C�g |
��R�o�C�g |
��S�o�C�g |
|
U+0000 .. U+007F |
00000000-0xxxxxxx |
0xxxxxxx |
|
|
|
|
U+0080 .. U+07FF |
00000xxx-xxyyyyyy |
110xxxxx |
10yyyyyy |
|
|
|
U+0800 .. U+FFFF |
xxxxyyyy-yyzzzzzz |
1110xxxx |
10yyyyyy |
10zzzzzz |
|
|
U+10000.. U+1FFFFF |
00000000-000wwwxx- xxxxyyyy-yyzzzzzzz |
11110www |
10xxxxxx |
10yyyyyy |
10zzzzzz |
���̌`���̓�����1�o�C�g�����ȊO�͈�ԏ�̃r�b�g(MSB)���[���ɂȂ�Ȃ����ƂŁA��ԏ�̃r�b�g���[���̕�����7�r�b�gASCII�����Z�b�g���̂��̂��Ƃ������Ƃł��B���������ĕϊ��̃A���S���Y���͋ɂ߂ĊȒP�ł��BURL�ϊ��ɍۂ��Ă�1�o�C�g�`���ȊO�̌`���ł͕K���e�o�C�g��%hh�ƃG�X�P�[�v�`���ƂȂ�܂��B
java.net.URLencoder.encode(String,�hUTF-8�h)�ɑ�����������JavaScript�Ŏ�������ۂ́A���̂悤�ȃA���S���Y���ɂȂ�܂��B
|
�������̕�����'\u0020�f�Ȃ�A�����'\u002b�f�ɒu�������� �@�@�����łȂ���A �@�@�@�@�������̕�����'\u002a�f�A'\u002d�f�A'\u002e�f�A'\u0030�f��'\u0039�f�A '\u0042�f�� '\u005a�f�A'\u005f�f�A'\u0061�f��'\u007a�f�łȂ���� �@�@�@�@�@�@���̕�����UTF-8�ϊ����A�e�o�C�g��%XX�̃G�X�P�[�v������ɕϊ����� |
java.net.URLdecoder.decode(String,�hUTF-8�h)�ɑ����������̃A���S���Y���́G
|
�������̕�����'+�f�Ȃ�A�����' �f�ɒu�������� �@�@����ȊO�̕����ŁA �������̕������G�X�P�[�v���������炱���UTF-8�ϊ����Ƃ��ă��j�R�[�h�����ɖ߂� �@�@�@�@�i����ȊO�̕����͂��̂܂܁j |
�ƊȒP�Ȃ��̂ł��B
�ȉ��ɂ��̊��ƁA�����pHTML�������܂��B�����̊��͏����̊g��4�o�C�g�����j�R�[�h(UCS-4)�ɂ��Ή����Ă��܂��B����HTML�t�@�C�����u���E�U�ŊJ���Ǝ��̂悤�Ȍ��ʂ�������ł��傤�B
|
JavaScript�ɂ��J2�v���b�g�t�H�[���݊�URL�G���R�[�h���Ƃ��̃e�X�g original
string : ���t������b ����Y
!"#$%&'()*+,-./01289:;<=>?@ABCXYZ[\]^_`abcxyz{|}~ URL
encoded string : %e5%86%85%e9%96%a3%e7%b7%8f%e7%90%86%e5%a4%a7%e8%87%a3+%e5%b0%8f%e6%b3%89%e7%b4%94%e4%b8%80%e9 %83%8e+%21%22%23%24%25%26%27%28%29*%2b%2c-.%2f01289%3a%3b%3c%3d%3e%3f%40ABCXYZ%5b%5c%5d%5e_%60 abcxyz%7b%7c%7d%7e URL
decoded string : ���t������b ����Y
!"#$%&'()*+,-./01289:;<=>?@ABCXYZ[\]^_`abcxyz{|}~ |
���ۂ̃A�v���P�[�V�����ɂ����ẮF
�A�j �E�F�u�E�T�[�o���́u�l�v�̕������java.net.URLEncoder.encode(String, �gUTF-8�h)���g����URL�G���R�[�h���ăN�b�L�[�́u�l�v�ɃZ�b�g����
�C�j �u���E�U��Window.document.cookie�Ŏ��o�����������
(�A) �u���O�v�Ɓu�l�v�Ɋ댯�ȕ������܂܂�Ă��Ȃ�����̂܂ܐV����decodeURL()�ɂ����邩�A
(�C) �u�l�v�̕������decodeURL()�ɂ����邩
���Đ�����������ɖ߂����ƂɂȂ�܂��B
�E�j Window.document.cookie��ύX����ꍇ�́A�V����encodeURL()���������ċt�̑�������܂��B�A��Window.document.cookie�ɉ����V�����u���O�v�̕������������Ƃ������Ƃ́A���܂ł̃N�b�L�[�ɐV�����N�b�L�[���lj������i�u���O�v�������Ȃ炻�́u�l�v�������������܂��B�j���ƂɂȂ邱���ɒ��ӂ��܂��傤�B
�Q�l�F
�N�b�L�[�̒����珊��̖��O�̒l�𒊏o������̗�ł��B
|
function loadCookie(name) {
var allcookies = document.cookie;
if (allcookies == "") return "";
var start = allcookies.indexOf(name + "=");
if (start == -1) return "";
start += name.length + 1; var
end = allcookies.indexOf(';',start);
if (end == -1) end = allcookies.length;
return allcookies.substring(start,end); } |
�N�b�L�[�́u�l�v��URL�G���R�[�h����Ă���ꍇ�́A
var
decodedValue = decodeURL(loadCookie(name));
�̂悤�Ƀf�R�[�h���܂��B�܂��u���O�v��u�l�v�ɗ\��ꂪ�܂܂�Ă��Ȃ����Ƃ��͂����肵�Ă���ꍇ��
var allcookies = decodeURL(document.cookie);
�Ƃ����ꊇ�����̎g�������\�ł��B
�v���O������
<HTML>
<HEAD>
<TITLE>j2 platform equivalent URL
encode/decode functions</TITLE>
<META HTTP-EQUIV="content-type"
CONTENT="text/html; charset=SHIFT_JIS">
</TITLE>
<SCRIPT LANGUAGE="JavaScript">
/* Function
Equivalent to java.net.URLEncoder.encode(String, "UTF-8")
Copyright
(C) 2002, Cresc Corp.
Version:
1.0
*/
function encodeURL(str){
var
s0, i, s, u;
s0
= ""; //
encoded str
for
(i = 0; i < str.length; i++){ //
scan the source
s
= str.charAt(i);
u
= str.charCodeAt(i); //
get unicode of the char
if
(s == " "){s0 += "+";} //
SP should be converted to "+"
else
{
if
( u == 0x2a || u == 0x2d || u == 0x2e || u == 0x5f || ((u >= 0x30)
&& (u <= 0x39)) || ((u >= 0x41) && (u <= 0x5a)) || ((u
>= 0x61) && (u <= 0x7a))){ //
check for escape
s0
= s0 + s; //
don't escape
}
else
{ //
escape
if
((u >= 0x0) && (u <= 0x7f)){ //
single byte format
s
= "0"+u.toString(16);
s0
+= "%"+ s.substr(s.length-2);
}
else
if (u > 0x1fffff){ //
quaternary byte format (extended)
s0
+= "%" + (oxf0 + ((u & 0x1c0000) >> 18)).toString(16);
s0
+= "%" + (0x80 + ((u & 0x3f000) >> 12)).toString(16);
s0
+= "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0
+= "%" + (0x80 + (u & 0x3f)).toString(16);
}
else
if (u > 0x7ff){ //
triple byte format
s0
+= "%" + (0xe0 + ((u & 0xf000) >> 12)).toString(16);
s0
+= "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0
+= "%" + (0x80 + (u & 0x3f)).toString(16);
}
else
{ //
double byte format
s0
+= "%" + (0xc0 + ((u & 0x7c0) >> 6)).toString(16);
s0
+= "%" + (0x80 + (u & 0x3f)).toString(16);
}
}
}
}
return
s0;
}
/* Function
Equivalent to java.net.URLDecoder.decode(String, "UTF-8")
Copyright
(C) 2002, Cresc Corp.
Version:
1.0
*/
function decodeURL(str){
var
s0, i, j, s, ss, u, n, f;
s0
= ""; //
decoded str
for
(i = 0; i < str.length; i++){ //
scan the source str
s
= str.charAt(i);
if
(s == "+"){s0 += " ";} //
"+" should be changed to SP
else
{
if
(s != "%"){s0 += s;} //
add an unescaped char
else{ //
escape sequence decoding
u
= 0; //
unicode of the character
f
= 1; //
escape flag, zero means end of this sequence
while
(true) {
ss
= ""; //
local str to parse as int
for
(j = 0; j < 2; j++ ) { // get two
maximum hex characters for parse
sss
= str.charAt(++i);
if
(((sss >= "0") && (sss <= "9")) || ((sss
>= "a") && (sss <= "f")) || ((sss >= "A")
&& (sss <= "F"))) {
ss
+= sss; //
if hex, add the hex character
}
else {--i; break;} //
not a hex char., exit the loop
}
n
= parseInt(ss, 16); //
parse the hex str as byte
if
(n <= 0x7f){u = n; f = 1;} //
single byte format
if
((n >= 0xc0) && (n <= 0xdf)){u = n & 0x1f; f = 2;} // double byte format
if
((n >= 0xe0) && (n <= 0xef)){u = n & 0x0f; f = 3;} // triple byte format
if
((n >= 0xf0) && (n <= 0xf7)){u = n & 0x07; f = 4;} // quaternary byte format
(extended)
if
((n >= 0x80) && (n <= 0xbf)){u = (u << 6) + (n & 0x3f);
--f;} //
not a first, shift and add 6 lower bits
if
(f <= 1){break;} //
end of the utf byte sequence
if
(str.charAt(i + 1) == "%"){ i++ ;} //
test for the next shift byte
else
{break;} //
abnormal, format error
}
s0
+= String.fromCharCode(u); //
add the escaped character
}
}
}
return
s0;
}
</SCRIPT>
</HEAD>
<BODY>
<PRE>
JavaScript�ɂ��J2�v���b�g�t�H�[���݊�URL�G���R�[�h���Ƃ��̃e�X�g
<SCRIPT LANGUAGE="JavaScript">
s
= "���t������b ����Y" + " !\"#$%&'()*+" + '\u002c'+
"-./01289:;<=>?@ABCXYZ[\\]" + '\u005e' + '\u005f' + '\u0060' +
"abcxyz{|}" + '\u007e';
document.writeln("original
string : "+s);
s
= encodeURL(s);
document.writeln("URL
encoded string : "+s);
s
= decodeURL(s);
document.writeln("URL
decoded string : "+s);
</SCRIPT>
</PRE>
</BODY>
</HTML>
7. JSP��JavaScript�Ԃ̃N�b�L�[�ɂ��f�[�^������
|
�Ō�ɊF�����ۂɃT�[�o�̃v���O�������쐬�����ۂ̎Q�l�Ƃ��āAJSP��JavaScript�ԂŃe�L�X�g���N�b�L�[����Ă���肷��T���v�������������܂��B |
����JSP���u���E�U���A�N�Z�X����Ǝ��̂悤�ȉ�ʂ�������͂��ł��B
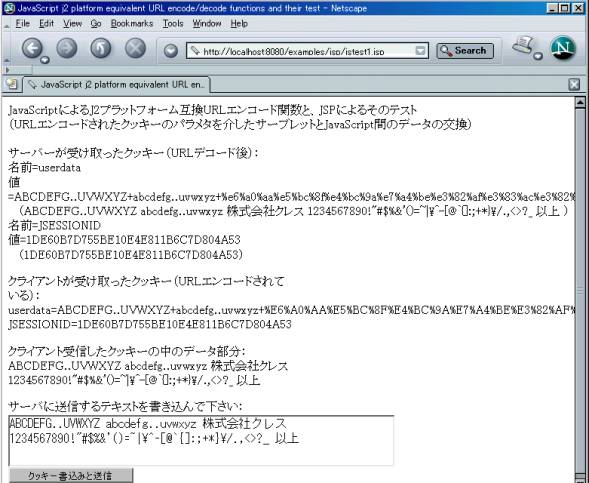
����͎��̂悤�ł��F
1. �ŏ��Ƀ��[�U�̓e�L�X�g�G���A�ɔC�ӂ̃e�L�X�g����͂��A�u�N�b�L�[�����݂Ƒ��M�v�̃{�^���������ƁA���̃e�L�X�g��URL�G���R�[�h���ꂽ�̂��huserdata�h�Ƃ����u���O�v�́u�l�v�Ƃ��ăN�b�L�[�ɃZ�b�g����T�[�o�ɑ����܂��B
2. �T�[�o�̓N���C�A���g���瑗���Ă����N�b�L�[�̓��e�̂��ׂĂ�悸�u���O�v�^�u�l�v�̃Z�b�g�Ƃ��ăN���C�A���g�ւ�HTML�e�L�X�g�ɏ������݂܂��B���̍ہu�l�v�̂ق���URL�f�R�[�h�������̂����ʂł������Ĉꏏ�ɏ������݂܂��B
3. �T�[�o���huserdata�h�Ƃ����u���O�v�́u�l�v�̕�����URL�f�R�[�h�������[�U����̃e�L�X�g���ēxURL�G���R�[�h���ăN�b�L�[�ɃZ�b�g���܂��B
4. �N���C�A���g�̂ق��́A�T�[�o�����HTML�e�L�X�g��\������Ƌ��ɁA�ꏏ�ɑ����Ă���JavaScript�ɂ���M�����N�b�L�[�̓��e�ŕ\�����A�����huserdata�h�́u�l�v�̕�����URL�f�R�[�h���ĕ\�����܂��B
5. ���M�����e�L�X�g�Ƒ���Ԃ���Ă����e�L�X�g����v����A��������M���o�������ƂɂȂ�܂��B
�{���ɃN�b�L�[���T�[�o�ƃN���C�A���g�o���ŏ�������ł��邩�S�z�ł����HURL�G���R�[�h���ꂽ�N�b�L�[�́u�l�v�����Ă��������B�G�X�P�[�v���ꂽ������JavaScript�̂ق��͏�������16�i�\���AJSP�̂ق��͑啶����16�i�\���ɂȂ��Ă��܂��B�����JavaScript��Number.toString(16)���\�b�h���������ŏo�͂���̂ɑ��AJava 2�v���b�g�z�[����URLEncoder.encode(String,�hUTF-8�h)�Ȃ郁�\�b�h�͑啶���ŏo�͂��邩��ł��B����őo����URL���������@�\���A���݊��������Ă��邱�Ƃ��m�F����܂��B
�Ȃ��A���A����s�����͂ł��܂��̂Ŏ����Ă��������BHTML�ł͂����̕����͕\������܂��A�������G���R�[�h��������Ă��邱�Ƃ��킩��܂��B�u���E�U�̐ݒ�ɂ���Ă͕��A(CR: %0d)�Ɖ��s(NL: %0a)�o�����N�b�L�[�ɓ���ꍇ������܂����A���s�݂̂̏ꍇ������܂��̂ʼn��s�����ɂ͒��ӂ��K�v�ł��B
�ȉ���JSP�y�[�W���Љ�܂��BJSP�̂Ȃ���JavaScript�������Ă���̂œǂ݂Â炢�Ƃ���͉䖝���Ă��������BJSP�̃v���O����������ԂŁAJavaScript�̕�����ŐF�������Ă���܂��B���̃v���O���������ۂɑ̌������̂��A�ǂ�Œ����Ɨ����������Ǝv���܂��B
|
<%@ page
contentType="text/html; charset=Shift_JIS" session="true"
import="java.net.*" %> <% Cookie[] cookies; Cookie cookie; cookies =
request.getCookies(); cookie = null; if (cookies != null){
for (int i = 0; i < cookies.length; i++){
cookie = cookies[i];
if (cookie.getName().equals("userdata")){break;} }
String encodedUserData = cookie.getValue();
String decodedUserData = URLDecoder.decode(encodedUserData,
"UTF-8");
cookie = new Cookie("userdata",
URLEncoder.encode(decodedUserData, "UTF-8"));
cookie.setMaxAge(300); //
give 5 minute to survive for the cookie
response.addCookie(cookie); } %> <HTML> <HEAD> <TITLE>JavaScript j2
platform equivalent URL encode/decode functions and their test</TITLE> <META
HTTP-EQUIV="content-type" CONTENT="text/html;
charset=SHIFT_JIS"> </TITLE> <SCRIPT
LANGUAGE="JavaScript"> /* Function Equivalent to
URLEncoder.encode(String, "UTF-8") Copyright (C) 2002 Cresc
Corp. Version: 1.0 */ function
encodeURL(str){ var s0, i, s, u; s0 = "";
// encoded str for (i = 0; i <
str.length; i++){ // scan
the source s
= str.charAt(i); u
= str.charCodeAt(i); // get
unicode of the char
if (s == " "){s0 += "+";} // SP
should be converted to "+" else
{
if ( u == 0x2a || u == 0x2d || u == 0x2e || u == 0x5f || ((u >=
0x30) && (u <= 0x39)) || ((u >= 0x41) && (u <=
0x5a)) || ((u >= 0x61) && (u <= 0x7a))){ // check for escape
s0 = s0 + s; //
don't escape }
else {
// escape
if ((u >= 0x0) && (u <= 0x7f)){ // single byte format
s = "0"+u.toString(16);
s0 += "%"+ s.substr(s.length-2);
}
else if (u >
0x1fffff){ //
quaternary byte format (extended)
s0 += "%" + (oxf0 + ((u & 0x1c0000) >>
18)).toString(16);
s0 += "%" + (0x80 + ((u & 0x3f000) >>
12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >>
6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else if (u > 0x7ff){ // triple byte format
s0 += "%" + (0xe0 + ((u & 0xf000) >> 12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >>
6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else {
// double byte format
s0 +=
"%" + (0xc0 + ((u & 0x7c0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
} } } return s0; } /* Function Equivalent to
URLDecoder.decode(String, "UTF-8") Copyright (C) 2002 Cresc
Corp. Version: 1.0 */ function
decodeURL(str){ var s0, i, j, s, ss, u,
n, f; s0 = "";
// decoded str for (i = 0; i <
str.length; i++){ // scan
the source str s
= str.charAt(i); if
(s == "+"){s0 += " ";} // "+" should be
changed to SP
else {
if (s != "%"){s0 += s;} // add an unescaped char
else{
// escape sequence decoding
u = 0; // unicode
of the character
f = 1; // escape
flag, zero means end of this sequence
while (true) {
ss = "";
// local str to parse as int
for (j = 0; j < 2; j++ ) {
// get two maximum hex characters to parse
sss = str.charAt(++i);
if (((sss >= "0") && (sss <= "9"))
|| ((sss >= "a") && (sss <= "f")) || ((sss >= "A")
&& (sss <= "F"))) {
ss += sss; // if hex,
add the hex character
} else {--i; break;}
// not a hex char., exit the loop
}
n = parseInt(ss, 16); //
parse the hex str as byte
if (n <= 0x7f){u = n; f = 1;} // single byte format
if ((n >= 0xc0) && (n <= 0xdf)){u = n & 0x1f; f =
2;} // double byte format
if ((n >= 0xe0) && (n <= 0xef)){u = n & 0x0f; f =
3;} // triple byte format
if ((n
>= 0xf0) && (n <= 0xf7)){u = n & 0x07; f = 4;} // quaternary byte format
(extended)
if ((n >= 0x80) && (n <= 0xbf)){u = (u << 6) + (n
& 0x3f); --f;}
// not a first, shift and add 6 lower bits
if (f <= 1){break;}
// end of the utf byte sequence
if (str.charAt(i + 1) == "%"){ i++ ;}
// test for the next shift byte
else {break;}
// abnormal, format error
}
s0 += String.fromCharCode(u); //
add the escaped character
} } } return s0; } /* Function to get cookie parameter
value string with specified name Copyright (C) 2002 Cresc
Corp. Version: 1.0 */ function
loadCookie(name) { var allcookies =
document.cookie; if (allcookies ==
"") return ""; var start =
allcookies.indexOf(name + "="); if (start == -1) return
""; start += name.length + 1; var end =
allcookies.indexOf(';',start); if (end == -1) end =
allcookies.length; return
decodeURL(allcookies.substring(start,end)); } /* Function to send the textarea data
throuth cookie Copyright (C) 2002 Cresc
Corp. Version: 1.0 */ function
sendThis(){ document.cookie="userdata="+encodeURL(document.inForm.text.value); //set data
window.location.reload();
// and reload this page } </SCRIPT> </HEAD> <BODY> JavaScript�ɂ��J2�v���b�g�t�H�[���݊�URL�G���R�[�h���ƁAJSP�ɂ�邻�̃e�X�g<BR> �iURL�G���R�[�h���ꂽ�N�b�L�[�̃p�����^������T�[�u���b�g��JavaScript�Ԃ̃f�[�^�̌����j<BR><BR> <% if (cookies
!= null){ %> <DIV STYLE="width:
50% word-break:break-all"> �T�[�o�[��������N�b�L�[�iURL�f�R�[�h��j�F<BR><%
for (int i = 0; i < cookies.length; i++){ %> ���O=<%= cookies[i].getName()
%><BR> �l=<%=
cookies[i].getValue() %><BR> �@ (<%= URLDecoder.decode(cookies[i].getValue(),
"UTF-8") %>)<BR> <% } } %> </DIV> <P STYLE="width:
50%"> �N���C�A���g��������N�b�L�[�iURL�G���R�[�h�������j�F<BR> <SCRIPT
LANGUAGE="JavaScript">
document.writeln(document.cookie); </SCRIPT> </P> <P STYLE="width:
50%"> �N���C�A���g��M�����N�b�L�[�̒��̃f�[�^�����F<BR> <SCRIPT
LANGUAGE="JavaScript">
document.writeln(loadCookie("userdata")); </SCRIPT> </P> �T�[�o�ɑ��M����e�L�X�g����������ʼn������F<BR> <FORM
NAME="inForm"> <TEXTAREA
ROWS="3" COLS="60" WRAP="soft"
NAME="text"></TEXTAREA><BR> <INPUT
TYPE="button" VALUE="�N�b�L�[�����݂Ƒ��M"
ONCLICK="sendThis()"> </FORM> </BODY> </HTML> |
�ȏ�